Concepts
Directed Acyclic Graphs (DAGs)
Directed Acyclic Graphs (DAGs) are a foundational structure for modeling workflows where tasks (nodes) are connected by directed edges (arrows) that define the execution order and dependencies. A DAG ensures there are no circular dependencies—once a task starts executing, the graph flows in one direction and cannot loop back. This acyclic nature is crucial for deterministic execution, allowing systems like FlowSynx to compute task order, validate graph integrity, and parallelize non-dependent tasks safely and efficiently.
In practice, DAGs enable clear visualization and reasoning about complex workflows involving conditionals, branches, merges, and independent execution paths. Each node represents a discrete task (e.g., file transformation, API call), while edges represent dependency constraints (e.g., Task B cannot start until Task A finishes). This structure enables features like error isolation, dependency-based retries, and fine-grained control over execution, making DAGs ideal for workflow orchestration in data pipelines, CI/CD processes, and distributed systems.
Below is an example of a DAG (Directed Acyclic Graph) workflow, illustrating a series of interconnected tasks that flow from a defined "Task 1" point through various processing stages and converge at an "Task 8" node, without forming any cycles.
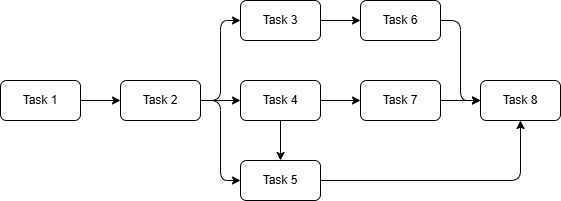
Task Dependencies & Execution Order
Task dependencies define the logical and temporal relationships between steps in a workflow. In a DAG-based system, dependencies are represented by the edges between tasks: a task may only execute once all its parent (upstream) tasks have completed successfully. This model guarantees that execution follows the defined structure, enabling intelligent scheduling, concurrency, and ordered flow management.
FlowSynx uses this dependency model to calculate the execution plan dynamically. It identifies independent tasks that can run in parallel and delays dependent tasks until their prerequisites are met. This ensures workflows behave predictably and optimally, especially in large pipelines with hundreds of steps. Proper dependency management also allows for features like partial retries, conditional branching, and more precise error localization when something goes wrong mid-flow.
Retry Policies & Error Handling
Retry policies define how the system should respond to failures during task execution. In a robust workflow engine like FlowSynx, each task can have custom retry strategies—such as fixed delays, exponential backoff, or limited retry attempts—configured declaratively. This allows workflows to be resilient to transient failures (e.g., temporary network issues, slow third-party APIs) without manual intervention.
Error handling complements retries by defining fallback behaviors, like alternative branches, alerts, manual approval steps, or graceful workflow termination. FlowSynx supports conditional error paths, enabling workflows to recover or adapt when specific failures occur. Together, retry and error handling mechanisms reduce operational burden, increase system reliability, and ensure critical workflows complete successfully even in the face of unpredictable runtime conditions.
Event-Driven Execution / Triggers
Event-driven execution allows workflows to start in response to external stimuli, such as a new file upload, a database change, an HTTP webhook, or a scheduled time. Triggers decouple workflow initiation from user actions, enabling true automation. In FlowSynx, events are often handled through specialized trigger plugins that monitor external systems or subscribe to message queues, firing workflows as soon as relevant conditions are met.
This model is ideal for reactive systems, where actions must occur as soon as something changes—like ingesting new data, responding to customer activity, or syncing systems in real time. Event-driven execution makes workflows more dynamic and efficient, supporting both polling and push-based mechanisms. It enables continuous processing and tight integration with systems like IoT, cloud storage, APIs, and databases, forming the backbone of real-time and autonomous operations.
Human-in-the-Loop Tasks
Human-in-the-loop tasks are manual intervention points within automated workflows, where human approval, data entry, or decision-making is required. These are essential for workflows involving compliance, quality control, exception handling, or multi-step business logic where automation alone cannot determine the next action. In FlowSynx, such tasks are explicitly modeled in the DAG and pause execution until the assigned user completes their part.
Micro-Kernel (Plugin-Based) Architecture
A plugin-based architecture is a software design pattern that emphasizes modularity and extensibility by allowing independent components (plugins) to be dynamically loaded and integrated into the core application. In FlowSynx, this architecture is central to the system's flexibility—each plugin encapsulates specific logic or capabilities, such as connecting to a cloud provider, processing a file, transforming data, or triggering a workflow. The core orchestration engine remains lightweight and generic, while plugins extend its functionality in a composable, loosely-coupled way.
This design allows teams to develop and deploy custom features without altering or recompiling the core system. Plugins can be versioned, isolated, and even sandboxed for security. FlowSynx supports runtime discovery and loading of plugins, enabling dynamic deployment and upgrades. Combined with plugin licensing, dependency injection, and configuration isolation, this architecture enables a highly scalable ecosystem where users can tailor the platform to their exact workflow needs—whether that means building proprietary integrations, leveraging community-contributed extensions, or enforcing strict organizational controls.